El aprendizaje automático (ML) está revolucionando la detección de fraudes, permitiendo que instituciones financieras y plataformas de comercio electrónico enfrenten el fraude de manera más efectiva. Ejemplos incluyen la reducción del fraude con tarjetas de crédito y phishing, con Citibank disminuyendo ataques en un 70 % y Walmart reduciendo robos en un 25 % mediante análisis de video.
En este artículo, exploramos los beneficios y desafíos del ML en la detección de fraudes y cómo puede proteger su negocio.
¿Cómo es la detección de fraude con Machine Learning?
En la detección de fraude, el machine learning es una colección de algoritmos de inteligencia artificial (IA) entrenados con tu información previa para sugerir reglas de riesgo. Entonces, puedes implementar estas reglas para bloquear o permitir ciertas acciones de usuario, como accesos sospechosos, robos de identidad o transacciones fraudulentas.
Cuando se está entrenando el motor del machine learning, se deben seleccionar casos previos de fraude y no fraude para evitar falsos positivos y mejorar la precisión de las reglas de riesgo. Mientras más tiempo se procesen los algoritmos, más precisa será la sugerencia de reglas.
Diferencia entre machine learning e inteligencia artificial
Los términos IA y aprendizaje automático a menudo se usan indistintamente. Sin embargo, aunque toda forma de aprendizaje automático cuenta como IA, no toda IA utiliza aprendizaje automático.
La IA es un concepto más amplio diseñado para crear máquinas que simulen el pensamiento humano. El aprendizaje automático es un subconjunto de la IA que permite a las máquinas aprender de los datos sin ser reprogramadas.
También vale la pena señalar que el aprendizaje automático tiene su propio subconjunto, llamado aprendizaje profundo, que emplea algoritmos y estructuras modelados según el cerebro humano.
Los beneficios del machine learning para el manejo de fraudes
Debido a que las máquinas pueden procesar un conjunto de datos grande con mayor facilidad que los humanos, se obtiene la capacidad de segmentar y analizar grandes cantidades de información. Esto significa:
- Detección más rápida y eficiente: El sistema identifica rápidamente patrones y comportamientos sospechosos que a los agentes humanos les tomaría meses establecer.
- Reducción del tiempo de revisión manual: De manera similar, el tiempo dedicado a revisar manualmente la información puede reducirse drásticamente cuando se permite que las máquinas analicen todos los puntos de datos por usted.
- Mejores predicciones con grandes conjuntos de datos: Cuantos más datos se le suministren a un motor de aprendizaje automático, más capacitado se vuelve. Si bien los grandes conjuntos de datos pueden dificultar la identificación de patrones para los humanos, ocurre lo contrario con un sistema impulsado por IA.
- Solución rentable: A diferencia de contratar más agentes de operaciones de riesgo, solo necesita un sistema de aprendizaje automático para procesar todos los datos, sin importar el volumen. Esto es ideal para empresas con picos y caídas estacionales en tráfico, transacciones o registros.
- Operación continua: Los algoritmos no necesitan descansos, vacaciones o sueño. Los ataques de fraude pueden ocurrir las 24 horas del día, los 7 días de la semana, y las máquinas pueden simplificar el proceso revisando casos evidentemente fraudulentos o aceptables.
Según un informe técnico de científicos de la Universidad de Yakarta, los algoritmos de aprendizaje automático lograron una precisión de hasta el 96 % en la reducción del fraude para negocios de comercio electrónico.
Descubra aquí cómo su negocio puede aprovechar la detección de fraudes mejorada con ML.
Hable con expertos
Diferencias entre el método blackbox y whitebox en machine learning
Si bien el aprendizaje automático tiende a ser un punto de venta para la mayoría de los proveedores de prevención de fraudes, no todas las soluciones son iguales. Cabe destacar una diferencia clave entre el aprendizaje automático de caja blanca y caja negra:
- Aprendizaje automático de caja blanca: El sistema ofrece explicaciones claras sobre por qué se sugirió una regla de riesgo, lo que facilita entender dónde está el riesgo y brinda flexibilidad a los gestores de fraude para mejorar su estrategia de prevención.
- Aprendizaje automático de caja negra: El sistema está diseñado para funcionar en modo “configurar y olvidar”, donde las decisiones son opacas y automatizadas. Es útil para pequeñas empresas que no necesitan ajustar sus reglas de riesgo.
¿Cómo utilizar machine learning para prevención de fraudes?
El término Machine Learning puede parecer un poco intimidante, pero empezar con un sistema algorítmico es bastante sencillo.
En este ejemplo, buscaremos reducir los fraudes de transacción (y por lo tanto, los costos de contracargo)
Introducir los datos de entrada
Cada sistema de IA o AML necesita datos de entrada para poder iniciar. En este escenario, serán datos de transacción como:
- Valor de la transacción
- SKU del Producto
- Tipo de Tarjeta de Crédito
- Etc.
También agregaremos información relacionada de cómo los clientes se conectan con el sitio:
- Información del IP
- Tipo de dispositivo
- VPN, proxy o uso de TOR
- Etc.
Ten en cuenta que cuanto más información tengas para empezar, más precisos serán los resultados. Esto es particularmente importante si tu software de prevención del fraude no permite campos personalizados, ya que podrías estar omitiendo información crucial.
Generar las reglas
El sistema de machine learning de SEON puede generar dos tipos de reglas:
- Reglas de parámetro simple, también conocidas como reglas heurísticas: un ejemplo de una regla de parámetro simple sería: bloquear el IP si es X.
- Reglas Complejas: aquellas que incluyen múltiples parámetros.
Cada regla listada muestra un puntaje de exactitud. Se puede ajustar el umbral de precisión para reforzar o aligerar las condiciones de activación.
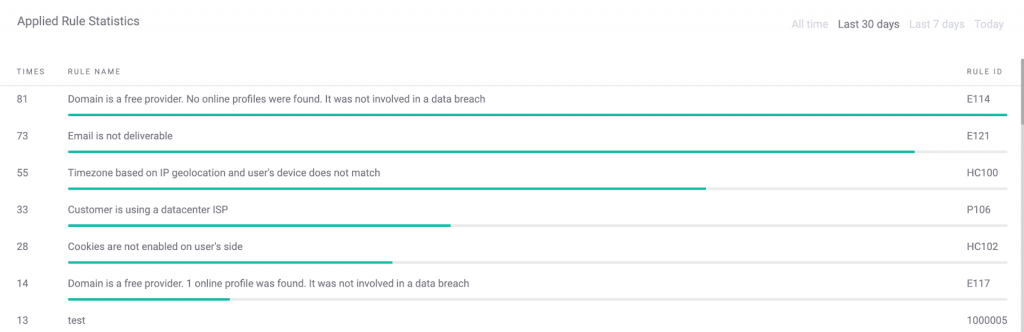
Tenga en cuenta que los nombres de las reglas son sumamente descriptivos, permitiendo entender porqué fue generada con un simple vistazo. Claramente se puede ver como todas las reglas son diseñadas para entender cómo el inicio de sesión del cliente puede afectar el valor de la transacción perdido por fraude.
Revisar y activar la regla
SEON te permite filtrar las reglas mediante cualquier dato, incluyendo su tipo y precisión de predicción. La parte de precisión es particularmente útil, y es calculada utilizando una matriz de confusión compleja.
Por defecto, las sugerencias de Machine Learning están desactivadas. Puedes activarlas rápidamente utilizando el switch de ON/OFF. También es posible crear y ajustar manualmente los umbrales para la regla de activación.
Entrenar el algoritmo
Proveer información como retroalimentación es clave para redefinir las reglas y obtener resultados más precisos. Con SEON, hay dos maneras de proveer retroalimentación y etiquetar las acciones:
- A través de la GUI: una simple y visualmente amigable manera de marcar acciones.
- Utilizando la Etiqueta API: puedes crear acciones programáticamente vía llamadas API.
Cualquiera que sea la manera como lo hagas, las acciones deberán ser marcadas como APROBADAS, REVISADAS o NEGADAS.

Los algoritmos se entrenan una y otra vez por sí mismos todos los días basados en los últimos 180 días de información válida. Puedes acceder a ellos en cualquier momento en tu motor de puntaje y back-end (donde manejas todas las reglas de riesgo).
Probar las reglas con información previa
Un buen software de prevención de fraudes debería permitirte visitar casos anteriores para revisar si las reglas han ayudado. Esto es realizado en un ambiente sandbox, donde puedes activar y desactivar las reglas para ser testigo de su precisión en persona.
Realizar una prueba creará una matriz de confusión basada en transacciones previas sobre el intervalo de tiempo seleccionado y destacará la proporción estimada de precisión de la regla. En el campo del machine learning una matriz de confusión o matriz de error es una tabla que permite visualizar el desempeño de un algoritmo. Esto te permite calcular la precisión sobre un rango de información específico, seleccionable desde la última hora, hasta el último año.
En las manos adecuadas, esto le da a los gerentes de fraude control completo sobre su estrategia de riesgo, permitiéndoles no solamente reducir si no también monitorear, probar y modificar resultados a voluntad.

Software de detección de fraude contratado VS machine learning en tu sitio
Mientras es completamente posible para un equipo talentoso construir sus propios modelos de machine learning, vale la pena considerar el tiempo, esfuerzo y costos involucrados:
- Costos de buscar talento: vas a necesitar científicos, ingenieros y especialistas en machine learning para construir los modelos.
- Tiempo para preparar la información: preparar y limpiar los datos sin procesar. Esto puede ser un proceso prolongado que puede tomar del 60% al 80% del tiempo entre recibir información de entrada y sugerir reglas de riesgo.
- Información no compartida: otra ventaja de contratar un servicio de machine learning es que se pueden beneficiar de información compartida de múltiples clientes. Esto no quiere decir que las reglas se van a aplicar a todos, sino que los que ofrecen este servicio utilizan su conocimiento para crear reglas de alta precisión de las que otros competidores se pueden beneficiar.
- Integración no lista para usar: es importante mencionar que integrar el machine learning con una estrategia de manejo de riesgos puede ser prolongado, complejo y costoso.
5 casos de uso de Machine Learning para detección de fraude
La prevención del fraude impulsada por IA es agnóstica de la industria. Solo necesita información para trabajar, y es la razón que por la cual encontrarás que ha sido implementada en una variedad de mercados diferentes como:
Tiendas en línea y fraude de transacciones
Analizar la información de miles de transacciones puede ser difícil. Es por eso que muchos gerentes de fraude de grandes compañías de comercio electrónico utilizan machine learning para entender por qué algunas transacciones no fueron marcadas como fraude por el sistema.
Y más importante aún, Juniper Research estima pérdidas de 50.5 mil millones de dólares debido a fraudes para los minoristas con tiendas en línea para el 2024.
Dicho esto, después de dejar que tu sistema de ML corra por un tiempo puedes aprender cuáles elementos son los más apuntados por los estafadores, qué tipo de información involucra el mayor riesgo y, por supuesto, qué pagos realizados con tarjeta deberían ser bloqueados para evitar tasas de contracargos y más.
Instituciones financieras y de cumplimiento
Las compañías fintech (financieras integrando tecnología) como instituciones financieras establecidas e incluso proveedoras de seguros, tienen requerimientos sumamente estrictos que deben cumplir para evitar multas reglamentarias. En otras palabras, necesitan verificar que están tratando con usuarios reales, no estafadores.
Sin embargo, también tienen que trabajar rápido para mantenerse competitivos. Así es como los estafadores se escabullen en la red. Con un sistema de machine learning en el lugar, muchas compañías pueden ganar información invaluable que hace que un perfíl se vea legítimo contra uno falso.
iGaming y abuso de bonificaciones o cuentas múltiples
Las compañías de juegos en línea, casinos y plataformas de apuestas deben asegurarse de que todos sus jugadores son reales. También tienden a ofrecer atractivas recompensas para nuevos clientes. Esto crea un doble incentivo para los estafadores de crear cuentas múltiples y reclamar las bonificaciones así como participar en un juego colusorio.
De acuerdo a TransUnion, en el 2021 se vio un incremento de 43% en los fraudes de identidad de apuestas en línea, lo que demuestra que es necesario tomar medidas ahora más que nunca.
Un sistema de machine learning puede ser utilizado para analizar información que apunta a comportamientos sospechosos por el usuario. Esto puede trabajar a tu favor para detectar bots, jugadores tramposos e incluso afiliados maliciosos que solo traen tráfico de mala calidad a tu sitio.
BNPL y robo de cuentas
Las cuentas de “Compra ahora, paga después” (BNPL) se están convirtiendo en las carteras digitales de internet. Si un estafador logra acceder a las cuentas de un usuario, puede adquirir bienes y/o servicios de manera ilegal. Esto se denomina robo de cuentas, o ATO.
La mejor manera de proteger las cuentas es entender cómo los usuarios acceden a la plataforma. El problema es que esto puede variar significativamente dependiendo del mercado, de la temporada y otros parámetros. Utilizando un motor de machine learning en tu punto de acceso de usuario puedes entender cómo autentificar mejor a tus usuarios para proteger sus cuentas en línea.
Pagos por puerta de enlace y contracargos por fraude
Este es otro ejemplo donde es sumamente difícil revisar manualmente cada transacción, especialmente cuando la rapidez de respuesta es esencial. Los pagos por puerta de enlace deben procesar miles de transacciones lo más rápido posible, lo que vuelve imposible emplear agentes humanos para revisarlas todas.
Un motor de machine learning puede actuar como un sistema analítico de monitoreo de fraude, donde puedes entrenarlo para detectar transacciones fraudulentas que incurrirán en costos de contracargo.
Descubre cómo podemos ayudar a hacer crecer tu negocio
Hable con expertos
¿Cómo SEON ayuda a combinar Machine Learning con revisiones manuales?
Claramente, dejar que un sistema de machine learning supervise tu estrategia de prevención de fraudes tiene muchas ventajas. Pero algunas veces tu enfoque no debería ser solo bloquear o aceptar acciones del usuario, sino también entregar toda la información correcta a tus analistas de riesgo lo más rápido posible. Siempre existen casos que caen en un área gris donde los mejores algoritmos no pueden funcionar por sí mismos.
Aquí es precisamente donde puedes utilizar el sistema whitebox de machine learning para sugerir reglas. Con nuestro motor que también incluye un poderoso enriquecimiento de información, tienes un completo entendimiento de las reglas donde el humano todavía tiene la última palabra.
La transparencia de SEON ayuda a tus analistas a tener una visualización total del problema y una solución potencial. Ellos pueden probar las reglas con tu propia información previa y modificarlas para obtener mejores resultados en un ambiente sandbox.
Efectivamente, esto quiere decir que obtienes lo mejor de los dos mundos: un poderoso sistema de IA impulsado para indicar dónde están los estafadores e inteligencia humana para supervisar las sugerencias.
En resumen, las máquinas son fantásticas a la hora de procesar información y conocimiento pero los humanos son mejores aplicándolo. Esta es la razón por la que SEON cree que combinar el conocimiento y el machine learning es la mejor manera de luchar contra los estafadores en línea.
Preguntas Frecuentes
Un sistema de detección de fraudes será capaz de detectar riesgos basados en el historial de tu información. Puede sugerir o implementar reglas para reducir el riesgo de fraude automáticamente.
Casi todos los sistemas de Machine Learning están completamente integrados con el sistema de prevención del fraude del cliente. El precio varía, e inclusive, puedes encontrar soluciones donde el pago depende del número de revisiones API que realices cada mes.
El Blackbox Machine Learning está diseñado para correr automáticamente bajo poca supervisión humana. El Whitebox Machine Learning, por otro lado, ofrece sugerencias claras y legibles que puedes aceptar, actualizar o negar basado en tu información.
También puedes estar interesado en:
- SEON: ¿Qué es la huella digital en internet y cómo funciona?
- SEON: Guía para la detección y prevención de fraudes online
- SEON: Compara los mejores 10 sistemas de gestión de fraude
- SEON: Listado de software de detección de fraudes
Relacionado
- Data Preprocessing vs Data Wrangling in Machine Learning Projects
- Juniper Research forecasts a $50.5B loss to fraud for online retailers by 2024
- TransUnion gaming report: 2021 saw a 43% increase in online gambling identity fraud