Most fake candidates do not look fake. They arrive with valid-looking email addresses, phone numbers that pass format checks and employment histories that read as plausible, which is exactly how they are designed. The problem is not that they look suspicious but that they look like everyone else.
Fake candidate fraud occurs when individuals or organized operations submit applications using fabricated, synthetic or stolen identities to harvest employer data, farm recruiter contacts or gain fraudulent employment inside a target organization.
This article shows product owners and trust and safety leaders at HR tech platforms how synthetic identities enter hiring workflows, which signals actually separate a fake candidate from a real one and how to build detection that improves as fraudsters adapt.
Key Takeaways
What Is Fake Candidate Fraud?
Fake candidate fraud sits at the identity layer of the hiring process. Unlike resume fraud, which involves misrepresenting qualifications or employment history, fake candidate fraud involves misrepresenting who the applicant actually is. The CV may be entirely plausible, but the person submitting it does not exist, or is not the person they claim to be.
For HR tech platforms, the distinction matters because it determines where in the process the problem needs to be caught. Resume fraud is an employer’s problem that surfaces during reference checks and background screening. Fake candidate fraud enters the system at registration or application submission, before any employer review begins.
The synthetic identity patterns behind fake candidate fraud are the same ones that have hit digital banks and online lenders for years. What has changed is the target. As financial platforms hardened their onboarding checks, the same infrastructure was redirected toward hiring workflows, where detection is newer and thinner.
How Synthetic Identities Get Into ATS Platforms
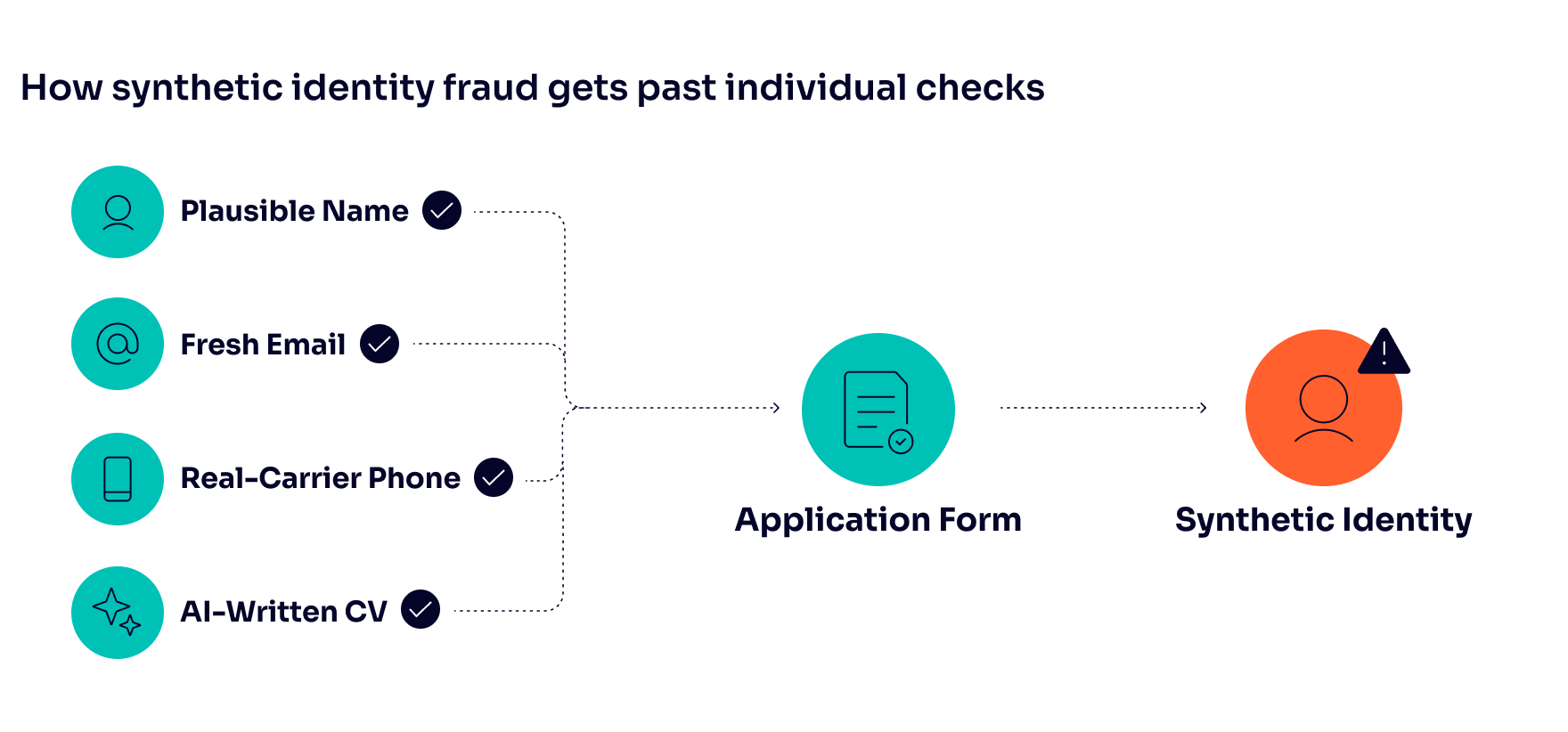
The entry point is almost always the application form. A name, an email address, a phone number and a CV: that is the surface area most ATS platforms expose at submission. For a fraud operation running at scale, that is enough.
Synthetic identities used in hiring are typically not built from stolen personal data. They are constructed from a plausible name, a freshly created email address and a work history assembled from publicly available job descriptions. The goal is consistency, not authenticity.
That distinction matters for detection. Each element passes the check it faces because each check only looks at that element in isolation, which means the identity holds up until you look at the signals that no individual check examines.
The scale at which this happens is what makes it a platform problem rather than an edge case. A single operation can generate hundreds of applications across multiple platforms simultaneously, testing which ones pass which checks and adapting the template accordingly.
Platforms with low submission friction and no enrichment layer are the ones that are repeatedly targeted. Generative AI has accelerated the problem: AI-written CVs are now indistinguishable from human-written ones, and AI tools lower the cost of producing plausible identities at scale. The detection gap between what looks real and what is real has never been wider.
The Signals That Reveal a Fake Candidate, and the Ones Fraudsters Have Learned to Game
Detection used to be simpler. A disposable email address, a phone number that failed carrier lookup or an IP address pointing to a data center was enough to flag a suspicious application. Modern fake candidate operations have adapted. They arrive with email addresses that pass deliverability checks, phone numbers registered to real carriers and IP addresses routed through residential proxies. The basic signals have been gamed because they are widely understood and easy to mimic.
What has not been gamed is depth. An email address created three days ago can pass every deliverability check and still have no associated social media presence, no data breach history and no digital footprint of any kind. That absence is the signal.
A phone number registered to a real carrier can still fail a CNAM lookup when the name on the number does not match the name on the application. A residential IP address can still be flagged even if the device behind it has submitted applications under multiple identities, because device signals persist across sessions even when fraudsters reset their browsers or rotate accounts. A stable device fingerprint built from hardware attributes and behavioral signals, rather than cookies, survives the identity changes that fool surface-level checks. When two applications share a device signature, the platform sees the connection regardless of the names on the CVs.
The challenge in fake candidate detection is not finding new signals but going deeper on the ones that exist, asking not just whether something is valid but whether it carries the history a real person would have accumulated.
“Closing the gap requires , including the signals, history and context that genuine identities accumulate naturally and fabricated ones cannot.”
Mira Sidhu, Director of Growth, Compliance Solutions
Email and Phone Enrichment: What Depth of Signal Actually Matters
Enrichment tools differ not in what they check but in how much they return. A platform evaluating point solutions for email and phone validation will typically encounter tools that answer one question per signal: Is this email deliverable? Is this number active? That level of checking was adequate several years ago, but the attack pattern has moved on.
The question that matters for fake candidate detection is not whether a credential is valid but whether it belongs to a real person with a real digital footprint. For email, that means checking account age, the number and type of platforms the address appears on and data breach exposure. An email address linked to a LinkedIn profile, a Spotify account and three data breaches from 2019 looks very different from one created last week with nothing attached to it.
Fraudsters have learned to add shallow social presence to address that gap, a TikTok account or a WhatsApp number, but sustained multi-platform history accumulated over years is what they cannot manufacture at scale. Whether the profiles linked to an address were created recently or have shown genuine activity over time is what distinguishes a coached synthetic identity from a real one.
For phone numbers, depth means going beyond carrier lookup. CNAM data provides a cross-check that catches a specific and common pattern: the name on the application does not match the name the number is registered to, and that mismatch, combined with a young email address and a residential proxy IP, significantly changes the risk picture.
The platforms that catch the most fake candidates are not the ones running the most checks. They are the ones whose checks return the most context per signal, then combine that context into a single risk decision rather than evaluating each data point in isolation.
LinkedIn Enrichment as a Cross-Validation Layer
LinkedIn enrichment is the signal most specific to professional hiring and the one that fake candidate operations have the hardest time defeating at scale. When an application email is submitted, enrichment checks whether it links to a LinkedIn profile and retrieves key data to compare against the CV.
The signals it surfaces include:
- Profile creation date and age
- Connection count and network depth
- Post activity and engagement history
- Career history and education match the CV
The gaps are often obvious. A CV claiming eight years of product management experience linked to a profile with 12 connections, no posts and a creation date from last month is a clear signal. One backed by years of activity, endorsements and a consistent network is not.
Building a convincing profile at scale is expensive and time-consuming. Operations running hundreds of simultaneous applications cannot do it for every identity, which is why LinkedIn enrichment functions as a filter even when other signals are inconclusive.
How to Build a Candidate Risk Score That Evolves With Fraud Patterns
A risk score built on fixed rules degrades over time. Fraudsters adapt to known thresholds, so if a score of 70 triggers a review, operations will calibrate their profiles to score 69. Accuracy requires the score to learn from what actually happens to candidates on your platform, not from a generic model built for a different industry.
The starting point is labeling. When a candidate is found to be fraudulent, that outcome is attached to the application record. The signals present at submission become training data: email age, phone enrichment output, device fingerprint and LinkedIn profile consistency. Over time, the model learns which combinations predicted fraud in your specific context.
This is where consolidated enrichment has a structural advantage over point solutions. If email intelligence comes from one vendor, phone data from another and device signals from a third, the labeling loop requires reconciling three separate data sets. Gaps between tools become gaps in the training data, and those gaps are exactly where coordinated fake candidate operations are designed to hide.
A single enrichment layer returning all signals in one API call means every outcome can be traced back to a complete signal picture. The model-suggestion component follows from this: rather than waiting for an analyst to spot a pattern, the model surfaces combinations it repeatedly sees and proposes rules based on them.
The analyst reviews, backtests and turns them on if they hold.
Frequently Asked Questions
What is fake candidate fraud?
Fake candidate fraud occurs when applications are submitted using fabricated, synthetic or stolen identities rather than genuine ones. Unlike resume fraud, which misrepresents a real person’s qualifications, fake candidate fraud misrepresents who the applicant is. It enters the hiring workflow at submission and operates at scale across multiple platforms simultaneously.
How is fake candidate fraud different from resume fraud?
Resume fraud involves a real person misrepresenting their qualifications, experience or employment history. Fake candidate fraud involves a fabricated identity submitting an application. The detection methods differ: resume fraud is caught through background checks and reference verification, while fake candidate fraud is caught through identity signal enrichment at the point of submission, before any employer review begins.
What signals does a platform use to detect a fake candidate?
The most reliable signals in combination are email age and social depth, phone CNAM match, IP and device context and LinkedIn profile corroboration. No single signal is conclusive on its own. Detection accuracy comes from combining them into a risk score that reflects the full picture of the candidate session rather than evaluating each data point in isolation.
Why do point solutions miss fake candidates that a consolidated layer catches?
Point solutions check individual signals in isolation and do not share context between them. A platform running separate tools for email, phone and IP validation has no way to combine those signals into a single risk decision or to train a model on the combined outcome. Gaps between tools are where coordinated fake candidate operations are designed to hide.
How do fraudsters defeat basic enrichment checks?
Modern fake candidate operations use email addresses that pass deliverability checks, phone numbers registered to real carriers and IP addresses routed through residential proxies. They have also learned to add a shallow social media presence to defeat first-generation enrichment. What they cannot easily fake is depth: years of consistent digital history across multiple platforms and a credible professional LinkedIn profile that holds up against the submitted CV.
How does a candidate’s risk score stay accurate over time?
A risk score stays accurate when it is trained on your platform’s actual fraud outcomes rather than a generic model. Every confirmed fake candidate becomes training data: the signals present at submission get labeled and fed back into the model. Over time, the score learns which combinations predicted fraud in your specific context, and the model suggests rules based on emerging patterns rather than waiting for an analyst to spot them manually.