More teams are discovering that they are fighting the same underlying risk using three different vocabularies — and it is starting to cost them real money. Globally, banks and fintechs now spend an estimated $206 billion every year on financial crime compliance, and that’s not even counting other regulated industries like gambling. Yet fraud losses and compliance penalties continue to climb, a clear signal that effort is not translating into shared understanding or outcomes. In the US alone, over 1.1 million identity fraud reports were filed last year, reinforcing that identity has become one of the primary battlegrounds for financial crime.
The fraud team is testing behavioral models, compliance is expanding its review of account activity and the IDV team is rolling out new ID documents and biometric checks as part of broad KYC programs, all powered by some flavor of AI. In a world where AI-driven criminal tactics and face-swap‑based ID attacks are surging, that language gap has shifted from a cultural annoyance to a structural weakness in your defenses.
One Risk Surface, Three Mental Models
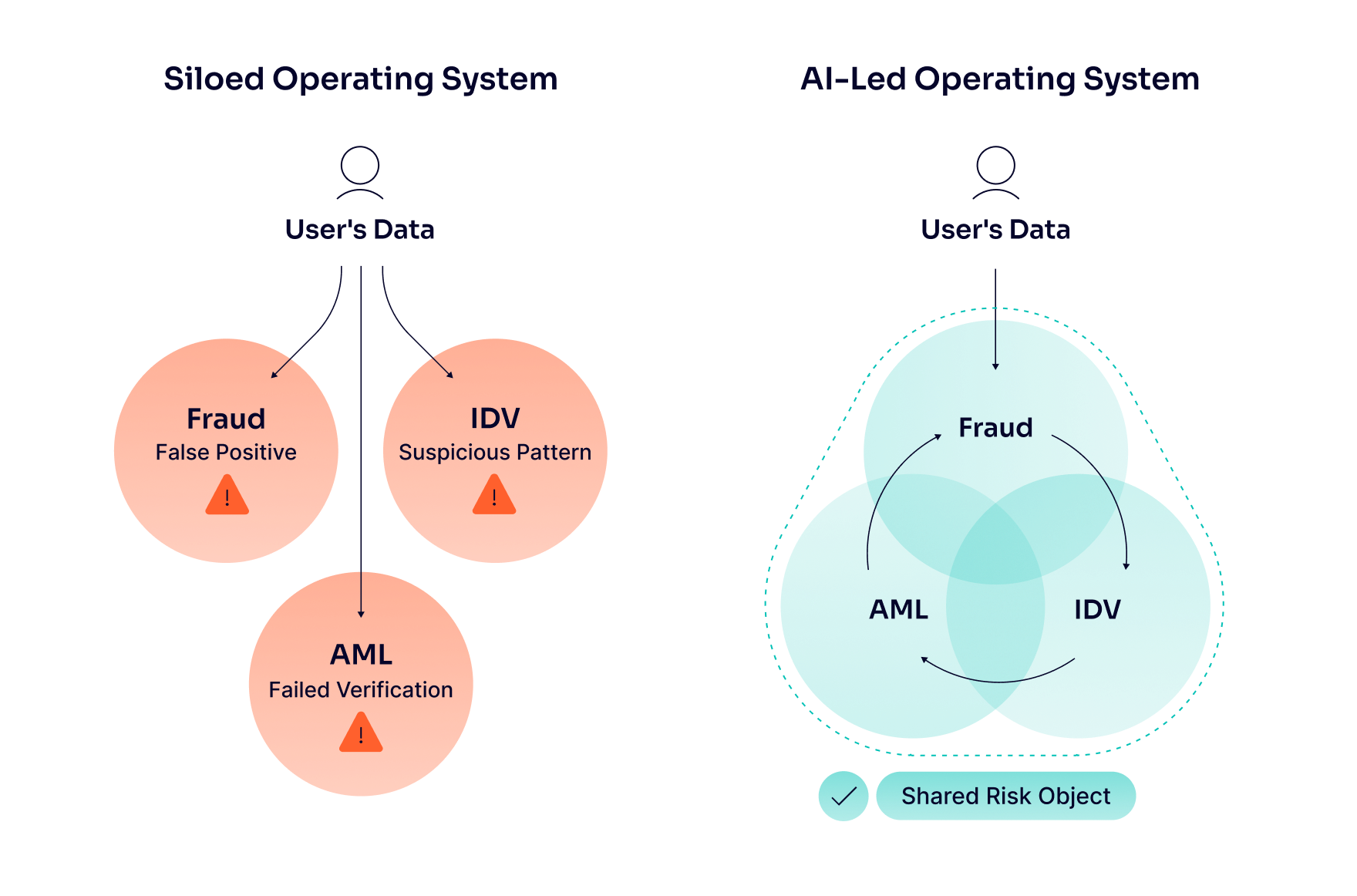
On paper, fraud, identity and AML functions all look at the same customer and the same journeys — onboarding, account login, payments and withdrawals. In practice, they inherit different mandates and mental modes: fraud teams are rewarded for cutting losses and abuse, AML teams for reducing sanctions and money-laundering exposure, IDV teams for keeping verification fast and conversion-friendly. Each function then builds its own dashboards, metrics and escalation paths around that lens so that the same risky session can be flagged as a false positive, a failed verification or a suspicious pattern depending on who is looking at it.
Those divergent mental models made sense when data, systems and mandates were clearly separated. Today, the stack and regulators are converging around a shared identity‑driven risk surface – the point at which you decide who a user is, how much you trust them and what they are allowed to do next. Yet the language and incentives have not kept up. That’s why an anomalous onboarding, a high‑risk login and a group of suspicious transactions often trigger three different conversations, three sets of investigations and three partially overlapping models, instead of one joined‑up assessment of the same underlying risk.
Where AI Makes Misalignment Worse (or Better)
Collectively, we’ve moved past the experimental AI phase, and it is now deeply embedded in financial crime programs. Fraud functions plug AI into device, behavior and transaction streams to spot anomalies in real time. IDV teams, meanwhile, are deploying AI into document checks, liveness and biometric matching to keep pass rates high without letting deepfakes and synthetic identities slip through, at a time when face-swap attacks against remote identity verification systems have surged by more than 700% in a single year. AML functions apply machine learning to transaction monitoring, name screening and SAR triage.
This parallel adoption looks like progress from the outside, yet it often hard‑codes the very misalignment you are trying to solve. Each team trains models on its own data, with its own labels and its own definition of suspicious – a failed selfie, an unusual payment route, a sanctions hit, or a risky account login can all be logged differently for the same customer and at the exact moment in time. The result is duplicated investigations, inconsistent decisions and blind spots, all of which increase operational costs, slow customer journeys and dilute accountability.
AI’s upside only really appears when the organization treats risk as a shared surface powered by an AI-led operating system, rather than a collection of siloed tools. Using isolated AI agents — one for IDV, another for enhanced due diligence and a third for transaction monitoring — creates blind spots. Instead, smart systems need a foundation that allows agents to understand everything holistically, starting with standardized frameworks like the Model Context Protocol (MCP) to ensure all data captured in the system is readable and actionable across functions.
When built on this unified foundation, shared features — like device reputation, behavioral patterns between onboarding and the first payment or IDV outcomes — can feed both fraud and AML models. This reduces false positives while increasing the likelihood of catching genuinely bad actors. Standard definitions and event taxonomies ensure that a high-risk login or onboarding anomaly has the same meaning and priority, whether you are looking at a fraud dashboard, an AML case or an IDV report.
Shared Risk Language and Operating Rhythm
The fastest way to align AI workflows for fraud, IDV and AML is not to redraw the org chart, but to standardize how risk is defined, measured and acted upon across customer journeys. Many institutions are moving toward a common financial‑crime taxonomy – a single set of risk categories, event types and severities that sits above fraud, KYC and AML – so everyone can map their controls and alerts to the same backbone. In practice, this means defining once what constitutes a high‑risk onboarding, a risky account login or a suspicious payment, and then letting each team attach its own fields and thresholds without changing the underlying language and for example, aligning on what signals trigger escalation versus monitoring — regardless of whether they originate in fraud, IDV or AML systems.
From there, you can design around a shared risk object: a consolidated customer or session profile that combines onboarding data, IDV results, device and behavioral signals, and transactional activity into a single view. Unified case management and investigations tooling make this concrete by pulling fraud and AML alerts for the same subject into a single workspace, cutting duplicate effort and making it easier to see blended typologies. IDV becomes the natural bridge in this model — it is the earliest, most structured touchpoint and its outcomes (who this person is, how they proved it, how confident you are) can be reused by both fraud and AML teams rather than re‑collected in different formats downstream.
Finally, a shared language only sticks if you embed it in the operating rhythm. That means joint risk reviews for critical journeys (onboarding, account login, first payment), cross‑functional runbooks for escalation, and standing forums where fraud, IDV and AML leads review the same metrics and model outputs against the same taxonomy.
From Separate Projects to a Shared Risk Narrative
The next wave of financial crime won’t be lost because your models were a version behind. It will be lost because your experts couldn’t agree on what they were seeing. Regulators, boards and even customers are converging on the same expectation: one joined‑up view of risk, one accountable story, no matter which team picked up the signal first.
That makes vocabulary a strategic choice and not an internal preference. If you can’t describe a risky onboarding, login or payment in the same terms across fraud, IDV and AML, you simply can’t govern it, and you or your AI automation certainly can’t explain it when something goes wrong. In an environment where regulators, boards and customers increasingly expect consistency and accountability, fragmented risk language is no longer just inefficient — it’s untenable.